Data Model Quality Framework
Automating validation in a multi-stage approval process to eliminate rework cycles and reduce approval time from one week to days
Context↑↓
Data models are a core deliverable for systems analysts — they define the structure that development teams build against and external stakeholders sign off on. In cross-organisational projects, every data model goes through a multi-stage approval chain: analyst creates the model, architect reviews the technical correctness, and an external client or contractor verifies that the model matches their requirements.
Each approval stage takes one to two days. If errors are found at any stage, the model returns to the analyst, and the cycle restarts. The further down the chain an error is caught, the more time is lost — and errors caught at the external approval stage are the most expensive: formal communication, waiting queues, re-scheduling reviews.
This case documents a process automation initiative that shifted error detection from the review stages to the entry stage, eliminating the most common causes of rework.
Problem↑↓
A team of analysts was producing data models for database design and external approvals. The approval cycle regularly took approximately one week due to repeated returns:
- Analyst sends the model to the architect
- Architect finds type errors or duplicates → returns to analyst
- Analyst fixes and re-sends → architect approves → forwards to the client
- Client finds range errors or missing required fields → returns to analyst
- Cycle restarts
The root cause was not a lack of skill — it was the nature of the work. Data models contain dozens of fields, each with a type, size, required flag, uniqueness constraint, default value, and allowed range. Manual entry across all these dimensions guarantees human-factor errors: typos, wrong selections, forgotten flags.
These errors were invisible at the point of entry and only surfaced during review — when they were most expensive to fix.
sequenceDiagram
participant A as Analyst
participant AR as Architect
participant C as Client / Contractor
rect rgb(255, 243, 243)
A->>AR: Data model v1
AR->>A: ❌ Wrong types, duplicates
Note over A,AR: 1–2 days lost
end
rect rgb(255, 243, 243)
A->>AR: Data model v2
AR->>C: External review
C->>A: ❌ Incorrect ranges, missing fields
Note over A,C: 2–3 days lost
end
rect rgb(255, 243, 243)
A->>AR: Data model v3
AR->>C: Re-review
Note over A,C: ~1 week total
end Error Analysis↑↓
Before designing a solution, the errors were classified by type to determine which can be caught automatically at the point of entry, and which genuinely require human judgement at review.
| Error type | Frequency | Automatable | Stage caught (before) |
|---|---|---|---|
| Wrong data type | High | ✅ Yes | Architect review |
| Duplicate field name | Medium | ✅ Yes | Architect review |
| Missing required flag | High | ✅ Yes | Client review |
| Invalid range or size | Medium | ✅ Yes | Client review |
| Typos in field names | High | ✅ Yes | Architect review |
| Wrong business logic | Low | ❌ No | Client review |
| Incorrect data mapping | Low | ❌ No | Client review |
The top five rows account for the majority of returns. All five are automatable. The bottom two require domain knowledge and must remain with human reviewers — but once the automatable errors are eliminated, reviewers can focus exclusively on these high-value checks.
Solution↑↓
The approach: shift error detection from Review to Entry. Build validation directly into the tool the analyst already uses, so that the most common errors become impossible to make.
Excel was chosen deliberately as an MVP — it was the tool already adopted by the team for data model delivery. No onboarding, no new tooling, no approval process. The validation logic is tool-agnostic and can be migrated to a dedicated application if the approach proves valuable at scale.
sequenceDiagram
participant A as Analyst + Validation
participant AR as Architect
participant C as Client / Contractor
rect rgb(240, 253, 250)
Note over A: Types, ranges, duplicates caught at entry
A->>AR: Clean data model
Note over AR: Reviews logic only
AR->>C: External approval
Note over C: Reviews mapping only
C->>AR: ✅ Approved
Note over A,C: 1–2 days total
end Validation Framework↑↓
The framework automates all five automatable error types identified in the analysis:
Data List Management — All data types live on a dedicated “Types” sheet. One update propagates to all dropdowns across the workbook. No free-text entry for types — selection only.
Data Validation — Dropdowns for Field Status, Type, Length/Size, Required, and Unique prevent input errors. Field names are checked for uniqueness automatically.
Color-Coded Indicators via conditional formatting:
- 🟢 Green — mandatory field correctly filled
- 🔴 Red — mandatory field empty or duplicate detected
- ⬜ Gray — optional field
- 🔵 Blue — value selected from list
- 🟠 Orange — mandatory list not selected
A legend at the top of the table makes the system self-explanatory — any team member can assess model health at a glance without reading documentation.
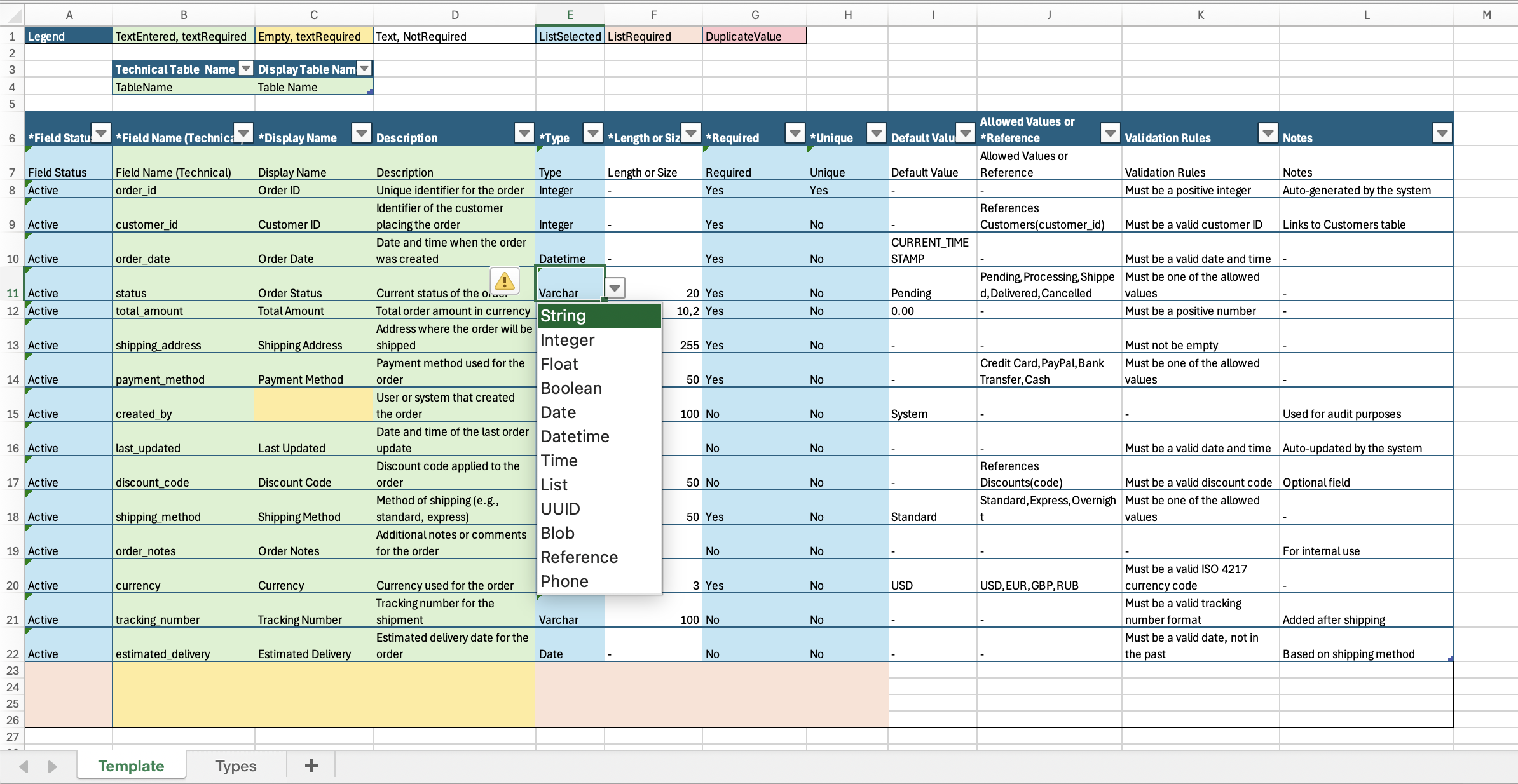
The template is available for download at the bottom of this page. Built with Excel conditional formatting, data validation, and Name Manager.
Result↑↓
Approval Process — Before and After
The team lead confirmed that the framework measurably accelerated the approval workflow after adoption. The specific acceleration depends on model complexity, but the structural change is consistent: reviewers no longer spend time on errors that the tool prevents at entry.
What Was Delivered
- Error classification — all recurring error types analysed and split into automatable vs. human-judgement categories
- Validation framework — 5 automatable error types eliminated at the point of entry
- Self-documenting template — color-coded, with legend, usable by any analyst without training
- Downloadable artifact — the template is open and reusable across projects
- Process shift — responsibility for data quality moved from Review to Entry, freeing architect and client reviewers to focus on business logic and mapping
Governance
The framework was adopted as the team standard for data model delivery. It serves as a single source of truth during the discovery and approval phase — ensuring that what reaches the architect and the client is structurally correct before the first review begins.
For teams that outgrow Excel, the validation logic transfers directly to any structured environment — Google Sheets, Airtable, or a dedicated data modeling application. The natural next step is to move the framework into a database-backed tool: store field definitions, types, and validation rules in a structured database, automate approval workflows, and version each model iteration — essentially, a database for designing databases. The framework is the approach, not the tool.